

Kielimalleihin pohjautuva tekoäly avaa tuottavuusjuoksun
Koneoppiminen ja tekoäly ovat olleet pinnalla jo vuosia, mutta ChatGPT räjäytti pankin: chattikokeilut ovat vakuuttaneet jo satoja miljoonia ihmisiä siitä, että tämä tulee olemaan heidän uusi työkaverinsa. Tästä se tekoälyn murros lähtee, tällä kertaa ihan oikeasti.
ChatGPT itsessään ei ole vastaus kovinkaan moneen ongelmaan. Se on vain tekoälykäs juttukaveri, jota voi käyttää sparrailemaan helposti kielellisesti kuvattavissa olevia ongelmia. Se ei kykene oikeaan luovuuteen, eikä ole tietolähteenä erityisen luotettava tai hyödyllinen. Tätä kritiikkiä on kuultu yllin kyllin, mutta se sivuuttaa asian ytimen. Ruuvimeisseli ei ole hyvä naulojen kanssa, eikä ChatGPT:llä kannata kirjoittaa gradua. ChatGPT on puutteistaan huolimatta uuden ajan airut – ja antakaapa kun perustelemme, miksi näin on.
Tekoäly on ollut jo täällä, mutta vain harvojen nähtävillä
Koneoppiminen (Machine Learning eli ML), neuroverkot ja monimutkaiset tekoälyalgoritmit yleistyivät liiketoimintakehityksen arjessa viimeisen vuosikymmenen aikana. Tekoälykiinnostuksen kasvua on tukenut kolme erillistä aaltoa:
- Teknologian kehittyminen: Tekoälytoteutuksiin soveltuvat valmiskirjastot ja jopa suoraan PaaS-alustat ovat alentaneet toteutuskustannuksia dramaattisesti verrattuna vaikkapa 20 vuoden takaiseen.
- Yritysdatan jäsentyminen: Kasvava ymmärrys laadukkaan datan merkityksestä on saanut yritykset keräämään ja jäsentämään tietoaan. Koottu laadukas data mahdollistaa yhä monipuolisemman analyysin.
- Käyttökohteiden lisääntyminen: Prosessien ja sovellusten kypsyminen luo uusia käyttökohteita. Esim. 10 vuotta sitten tyypillistä verkossa toimivaa itsepalvelukäyttöliittymää olisi ollut vaikea ohjata datavetoisesti; tänä päivänä vaikkapa Google generoi jatkuvasti mainostekstivariaatioita, ja hakee automaattisesti vetävimmän muotoilun.
Perinteisen ML/AI-tekemisen haasteena on kuitenkin ollut vaadittava erityisosaaminen. Vaikka data sciencen perusteet voi edelleen opiskella kohtuuvaivalla, sopivien mallien kouluttaminen, soveltaminen ja hallinnointi MLOps-praktiikoineen laajassa mitassa vaatii organisaatiolta syvää panostusta.
Kielimalli tuo tekoälyyn käytettävyyttä ja generalismia
Large Language Model – siis laajaan tekstuaaliseen opetusaineistoon perustuva neuroverkko – on tekoälyratkaisu, joka hahmottaa maailman nimenomaan tekstin tulkinnan kautta. Se ei tiedä, mikä painesensorin lukema ennakoi paperikoneen huoltotarvetta, eikä se osaa muuntaa verkkokaupan selailuhistoriaa loistaviksi tuotesuosituksiksi, mutta ihmisen kanssa kommunikoinnissa se on ylivoimainen.
Oheinen infografiikka kuvastaa kehityskulkua, jolla suurten kielimallien aikaan on päädytty. Saat suurennettua infografiikan klikkaamalla sitä.
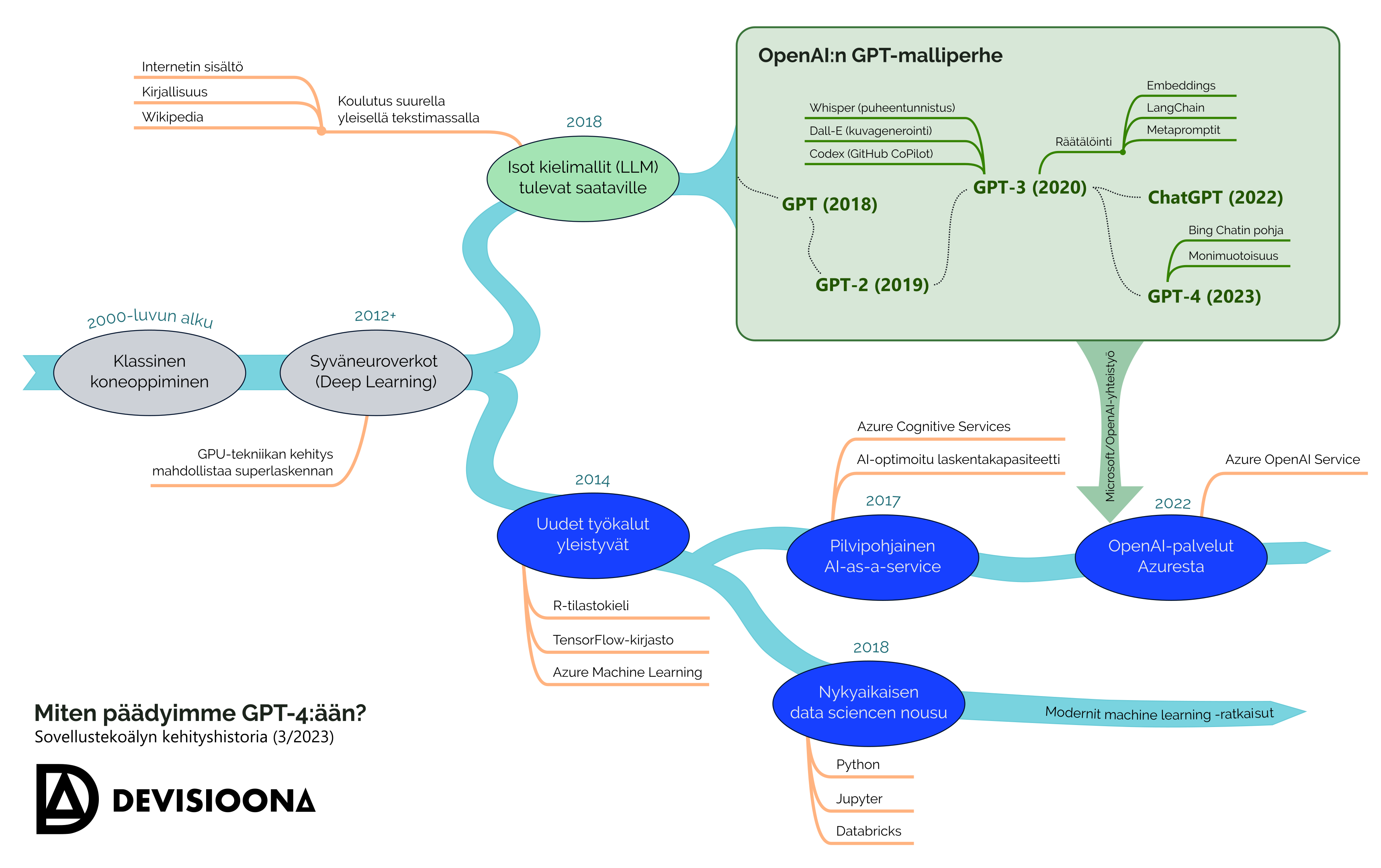
LLM-ratkaisu ei tarvitse syötteekseen täsmällisesti mietittyä datamallia attribuutteineen, vaan sitä voidaan käskeä puhtaasti tekstin keinoin. Siinä missä perinteistä koneoppimismallia opetettaisiin tunnistamaan vaikkapa asiakaspalautteen sävyä syöttämällä sille tuhansia palautteita ja niistä tehtyjä sävyarvioita, LLM-malli osaa ilman valmennustakin vastata suoraan kysymykseen: ”Asteikolla 1–5, kuinka positiivisena pidät seuraavaa asiakaspalautetta? <asiakaspalautteen teksti>”
LLM-malleista tunnetuin on yhdysvaltalaisen OpenAI-yrityksen kehittämä GPT-3, johon mm. ChatGPT pohjautuu. GPT-3:n syötteenä on ollut valtava määrä internetin tekstiä – mm. koko Wikipedia – ja vino pino kirjoja. Siinä missä monien koneoppimismallien koulutus kestää tunteja ja maksaa satasia tai tonneja, epävirallisten arvioiden mukaan GPT-3-mallin kouluttaminen on maksanut jopa 150 miljoonan euron edestä pelkkää laskentatehoa – ja tuotekehityskustannukset päälle. Juuri tässä piilee kielivetoisen mallin potku: Joku muu on maksanut massiiviset investointikustannukset kattavan kieliymmärryksen mahdollistamiseksi, jotta voimme esittää toiveemme tekoälylle ilman oman mallin kouluttamista.
Mutta millä tiedolla malli vastaa? GPT-malli on ahminut internetin ja kirjoja, mutta ei se tiedä mitään yrityksesi asiakasdatasta, Pohjanmaan aikasarjoitetusta säähistoriasta tai traktorin moottorin käyntiparametreista. Kuten ChatGPT-kritiikki on osoittanut, tekoälyn hallusinointi johtaa joskus myös tilanteisiin, joissa kielimalli on väärässä sellaisistakin asioista, jotka sen opetusmassassa on kerrottukin. Miksi neuroverkko näin toimii, sitä eivät täysin tiedä tutkijatkaan.
Tätä juttua kirjoitettaessa (14.3.2023) julkaistiin uusi GPT-4-malli, joka on entistä laajapohjaisempi, sävykkäämpi ja harkitsevampi. Ensikokeilujen perusteella GPT-4 ymmärtää tekstin vivahteita ja seuraa aiempaa taidokkaammin monimutkaisiakin ohjeita, mutta peruskäyttö ei ole muuttunut. Kiinnostava uusi suunta on kuitenkin monimuotoisuus (multi-model): GPT-4 pystyy tekstin lisäksi tulkitsemaan myös kuvia.
LLM-malleja ei siis kannata ajatella hakukoneina – paitsi jos Googlen Bard tai Microsoftin Bing Chat onnistuvat nämä toiminnallisuudet siihen päälle hiomaan. Ne eivät myöskään ole datanmurskaajia, jotka ratkaisevat asiakassegmentoinnin visaisimmat ongelmasi. Miten siis saada niistä hyötyä?
Lisäaivot niille, jotka niitä opettelevat käyttämään

Yksinkertaisin tapa hyödyntää kielimalleja liittyy nimenomaan suoraan tekstiin. Tänä keväänä Teams Premium alkaa muodostaa palaverimuistiot itse. ChatGPT:tä tai muita GPT-pohjaisia sovelluksia voi käyttää jo nyt varsin hyvin tekstin analysointiin ja tuottamiseen (vilkaise syksyn blogijuttuamme – ja tilanne on jo kehittynyt siitäkin!). Microsoftin Edge-selaimen esiversiossa Bingin GPT-pohjaisen tekoälyn voi pyytää vaikkapa tiivistämään luettavan sivun ranskalaisiksi viivoiksi.
Tällaiset käyttötavat tuovat käyttäjälle lisää kognitiivista kapasiteettia: isompia tekstimassoja voi käsitellä, tuottaa ja jalostaa, kunhan osaa. Microsoft julkaisee tällä viikolla uutisia Officen AI-integraatiosta, ja se tuo tekoälyn entistä lähemmäs tietotyöläisen arkea: kun jatkossa esim. Wordin voi pyytää täydentämään tarinaa tai Outlookin vaihtamaan viestin tyylilajia, tietotyö yksinkertaistuu ihmisaivojen keskittyessä enemmän tavoitteisiin ja vähemmän tekniikkaan.
Aiemmin LLM-ratkaisuista käytettiin nimeä luova tekoäly. Nimi on kuitenkin oikeastaan huono, sillä varsinaista luovuutta mallilla ei ole. Toisaalta: Jos pyydät mallilta 20 ideaa siitä, mitä näkökulmia vaikkapa tuulivoiman tehokkuutta koskevaan lehtiartikkeliin kannattaisi upottaa, saat luultavasti 5–10 hyvää ajatusta. Vartin jatkotyöstöllä olet saanut jokaisesta näistä generoitua pienen sisältörungon, joiden pohjalta ryhtyä töihin. Tuliko valmista artikkelia? Ei, eikä tulos sellaisenaan myöskään muistuta omaa tyyliäsi. Mutta jos kärsit aloittamisen vaikeudesta – ns. valkoisen paperin kammosta – niin siitä pääsit juuri yli heittämällä.
Kielimalli älykkäiden sovellusten taustalla
Ohjelmistokehittäjien kannalta kielimallit ovat tärkeä askel. Varsinaisten data science -ratkaisujen upottaminen omiin sovelluksiin on monesti ollut sekä arkkitehtuurisesti, osaamisellisesti että kustannusmielessä vaikeaa. OpenAI:n ja Microsoftin yhteistyön myötä GPT-mallit ovat saatavilla nopeiden ja halpojen rajapintojen takaa saatavilla sovellusten tueksi, ja tämä mahdollistaa älyn ripottelun sovelluksiin ilman varsinaista datavetoista koneoppimisprojektia. Muutamia esimerkkejä asioista, joita Devisioonassa olemme tutkineet ja toteuttaneet viime kuukausina:
- Monimutkaisen tekstidokumentin jäsentäminen selkeiksi tietorakenteiksi
- Syötetyn tekstin kielioppikorjaukset
- Automaattikäännökset eri kielillä
- Tuotekuvausten muodostaminen raakadatasta
- Käyttäjien lähettämien viestien suodattaminen asiattomuuksista
- Kielellisen ja tyylillisen palautteen antaminen käyttäjän kirjoittamasta tekstistä
Käytännön toteutusten osalta keskiössä on myös Azure-pilviympäristö. Microsoftin Azure OpenAI Service tarjoaa GPT-3-rajapintoja Azure-ympäristössä – periaatteessa sama palvelu kuin OpenAI:lla, mutta palvelut saa omaan hallittuun ja suojattuun Azure-ympäristöön, toivomaasi datakeskukseen Microsoftin GDPR-takuiden taakse.
Oma data mukaan ratkaisuihin

Kaikki edellä mainittu kuulostaa hyvältä, mutta ei vielä vastaa tärkeään ydinkysymykseen: miten saada organisaation oma tietomassa mukaan tekoälymalliin? Lähestymistapoja on useita, mutta tyypillisesti LLM-mallin täydentäminen omalla datalla ei kuulu niihin halvimpiin. Ainakin tähän asti julkaistun hinnoittelun perusteella vaikuttaa nimittäin siltä, että suurten kielimallien räätälöityjen versioiden ajokustannuksissa puhutaan minimissään neljännesmiljoonasta vuositasolla.
Täydentäviä vaihtoehtoja kuitenkin on. Mallien tarjoamia syötteitä voidaan ohjata ns. kehotesuunnittelulla (prompt design) – antamalla tekoälymallille ohjeistusta siitä, miten sen oletetaan käyttäytyvän ja millaisia vastauksia antavan. Tämä on jo nyt mahdollista varsinkin ChatGPT-rajapinnoissa, mutta asia on uusi ja valmista osaamista tarjolla vain vähän. Tällä hetkellä vaatii huomattavasti osaamista opettaa esimerkiksi ChatGPT-malli vastaamaan vain toivottujen rajojen puitteissa, mutta jokainen viikko tuntuu vievän osaamista eteenpäin.
Tyylillisten seikkojen ohella on tärkeää kehittää myös datan saatavuutta. Jos mallin pitäisi osata esimerkiksi luonnostella vastauksia tarjouspyyntöihin automaattisesti, se tarvitsee paljon informaatiota yrityksen CRM:stä, yritysrekistereistä ja muualta. Oman tiedon liimaamista voidaankin tehdä opettamalla LLM-malli kysymään tietoa ulkoisista lähteistä – jälleen yksi taiteenlaji, jota on harrastettu vasta hyvin vähän aikaa, mutta jossa LangChain-niminen avoimen lähdekoodin kirjasto näyttää hyvää suuntaa.
Jos oma data on lähtökohtaisesti tekstimuotoista – esimerkiksi vaikkapa oman tuotteen käyttöohjeita – sen voi tuoda osaksi LLM-mallia myös ns. embeddings-tekniikalla. Embeddingsin matemaattis-loogisesti monimutkaiset vektorimuunnokset on kääritty käteviin Python-kirjastoihin, mutta niidenkin oikea soveltaminen vaatii vielä kokeilua ja huolellista suunnittelua.
Tällä hetkellä oman datan LLM-integraatioon ei ole selkeitä parhaita käytäntöjä. Kustannustehokkaat optiot löytyvät kehotesuunnittelun, ketjutettujen kyselyiden ja ulkoisten tietolähteiden yhdistämisen kaltaisista ratkaisuista. Kun luemme tätä blogipostausta kolmen kuukauden päästä, maailma voi näyttää jo kovin erilaiselta.
Rajoitteita ja huolia
ChatGPT on toistaiseksi maailmanhistorian nopein tuote, joka on saavuttanut 100 miljoonaa käyttäjää (kahdessa kuukaudessa!), mutta vielä on matkaa tekoälyeuforiaan. Viimeisen vuoden kokeilut ovat olleet lupaavia ja muuttuvat joka kuukausi lupaavammiksi, mutta pilviäkin on edessä.
Mallien räätälöintihaasteiden lisäksi vaikeusastetta nostaa vaatimustason nousu. Mitä itsenäisempiä järjestelmistä halutaan tehdä, sitä varmempi pitäisi olla niiden lopputuloksesta. Uskaltaako LLM-mallin antaa tehdä suoraa asiakaspalvelua? Onko riskinä hallusinaatio omista tuotteista ja sitä kautta pettynyt asiakas, vai voiko botista tulla maineriski, jos joku onnistuu innostamaan sen vaikka puhumaan rumia kilpailijoista? Neuroverkon tiet ovat tutkimattomat, ja oman arvomaailman iskostaminen sen mieleen vaatii erittäin huolellista pohjatyötä – vieläpä kehotesuunnittelun kaltaisilla alueilla, joissa valmista osaamista ei oikein ole.
Devisioonan kanta tällä hetkellä on, että LLM-malleja ei vielä kannata päästää autonomisesti tekemään juuri mitään. Ihmisen kannattaa tarkastaa lopputulokset, kunnes jonkin ratkaisun toimivuudesta ollaan täysin vakuuttuneita. Näitä ongelmia kuitenkin pohditaan tällä hetkellä kiivaasti ympäri maailman, ja jo muutamassa kuukaudessa myös luottamus voi olla huomattavasti paremmalla tasolla.
Haluatko sparrailla älykkäiden sovellusten mahdollisuuksia organisaatiossasi? Mietityttääkö tekoälyn vastuullisuus ja tietosuoja? Ota yhteyttä!

Jounin lähes 30 vuoden IT-uran ydin on ollut koodaamisessa, mutta nykyisin hän keskittyy teknologiastrategiaan, auditointeihin ja hankemäärittelyihin. Jouni on Devisioonan toimitusjohtaja ja yksi maailman 180 Microsoft Regional Directorista. Hänet on myös palkittu vuoden 2023 Microsoft-vaikuttajana työstään Azure-pilven ja tekoälyn parissa.


